How Not to Use Prometheus: Storing Events
In this post, we’re going to start designing a system to query bank and card transaction using the Prometheus Time Series Database (TSDB), based on a small project I previously created to do some analysis of my personal finances with SQL queries. The project does some labelling of transactions and uses those labels to make some aggregations on incomings and outgoings over time.
I believe that, to understand a technology, you have to understand what you shouldn’t do with it, as well as what you can. This understanding is particularly important when moving from a SQL database to a more specialized form of data storage, as is the case here.
While Prometheus is a TSDB, this is not the use case that Prometheus was designed to solve. It is designed to enable querying & alerting on system metrics specifically. While it is possible for technologies to work well outside their original use-case, it will not be surprising that, along the way, we run into some problems. At what point do we decide that we chose the wrong tool for the job?
Data Ingestion
Let’s suppose we have one bank account and two separate credit cards. Prometheus has a pull-based ingestion model, so we would like to specify 3 endpoints in the scrape config for it to connect to:
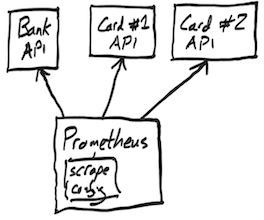
Prometheus would then scrape each API for data every 60 seconds (by default).
However, two problems immediately arise:
- We need to authenticate with any banking API to request data
- Prometheus requires endpoints to expose data as metrics in a specific format. We need to get the banking APIs to speak this language somehow
Combined, these problems mean that we need a separate component to serve as an adapter.
Daemon or Batch Job
The most seamless process for ingesting data might appear to be to write a daemon process that Prometheus connects to. Behind the scenes, this continually polls the banking APIs looking for new transactions.
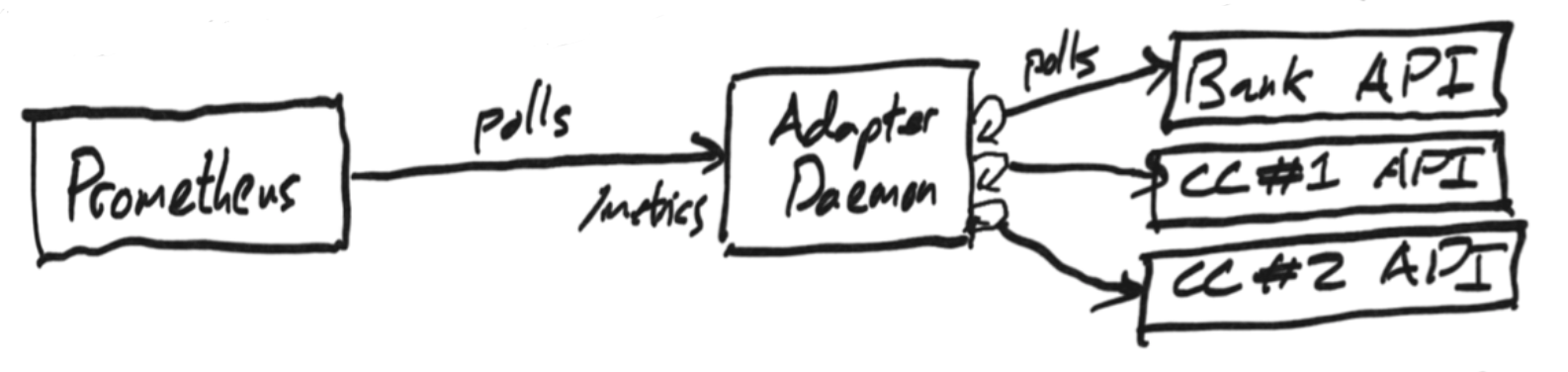
With our default Prometheus config, this means we will always be able to query for any transaction data more than 2 minutes old.
However, using a program to connect to a banking API - if one is even available - will be difficult. Moreover, such a highly automated process is not necessary for analysis of personal finances. It’s perfectly adequate to manually export data and then run a batch job to load it into Prometheus.
To get data from batch jobs, Prometheus requires us to use the PushGateway:
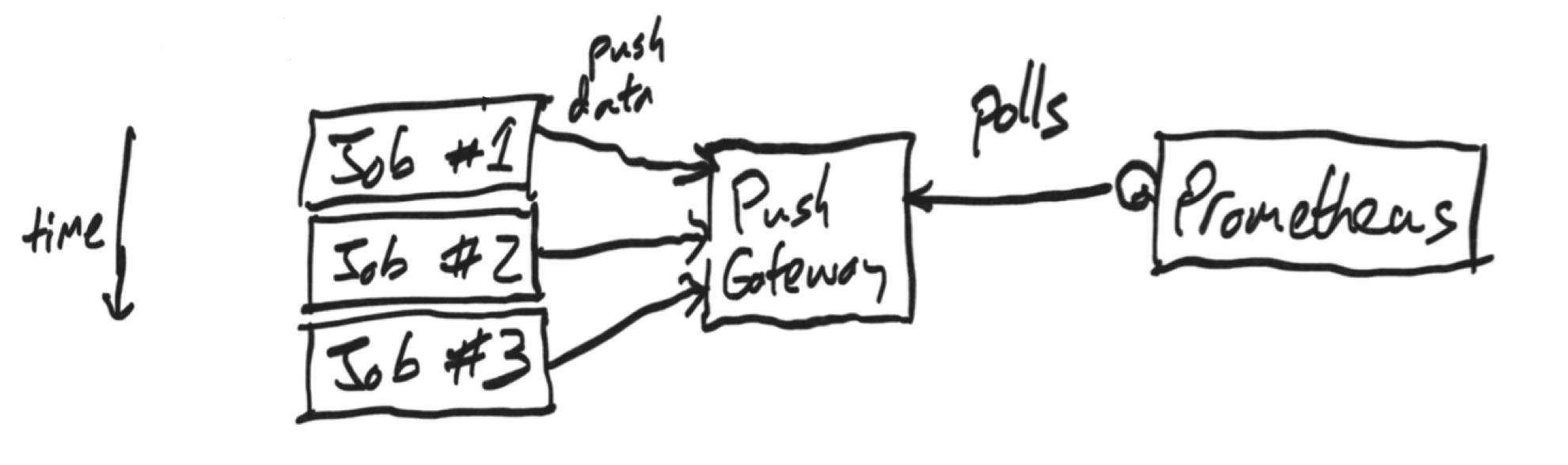
So, we can download all the required data, then run a script, which pushes metrics to the PushGateway. And Prometheus is scraping the PushGateway. There are more details to get into, but this is fundamentally a workable approach to ingestion.
Data Model
Normally transaction exports come in a tabular format, with each entry something like this:

In Prometheus, data models are not tabular (relational), so we have to do some work to translate them. Let’s take the fields one-by-one, starting from the left:
Date / Time
This field cannot be used in Prometheus. Prometheus cannot be used to import historical time-series, instead it continually scrapes the current data on each node and associates it to the scrape time. The choice to exclude this functionality in Prometheus was made to optimize for metrics at the expense of generic time-series use-cases.
TX Type | Category
Entries may come with a ‘TX Type’, which distinguishes regular card transactions from cash withdrawals or Direct Debits, etc. Since there are a small number of possible values, this is a good fit for a label. Every combination of label values on a metric creates a separate time-series in Prometheus, which is why it is recommended to select only a small number of labels.
The category field may also be present to denote categories of spending. Similarly, it can be represented with a label in Prometheus. One complication here is that this field (label) may not be present across all our data sources, while we would like to be able to query all our data using the same expressions. We can do this - at the cost of adding some complexity to our query.
Description
This field is rather different from the previous two, as very few transactions share an identical description. Descriptions contain a vendor name, but also contain all other sorts of information: location, date, forex fees, etc. For this reason, it’s a field that’s useful in more niche or ad-hoc queries but is not a good fit for a Prometheus label. This field is what people refer to as a high cardinality field. If we were to assign it to a label, we would run into memory limits with a relatively small amount of data, due to the overhead of creating additional time-series for each distinct value.
Amount | Balance
Now we get to the meat of the matter. Transactions, ultimately, are all about the amount. But this is where we really run into trouble. Prometheus primarily expects data to be expressable as a counter or a gauge. A counter is an amount that always increases over time, like a count of HTTP requests received. A gauge is a single number representing the state of a system, which may increase or decrease over time. An example would be the amount of memory in use.
Transactions, as a type of event data, do not fall into either category. Prometheus does give us some additional data types we can use to model this time of data: histograms and summary types. Both present a count of events, but use an extra dimension to count data within buckets or quartiles, respectively. In our case, this would allow us to bucket transactions by amount; we could count the number of small transactions vs medium or large transactions. It may give interesting results, but it isn’t the type of query I intend to do.
We cannot fit our raw data into Prometheus primitives and manipulate them to do our queries based on categorisation. However, to query against transaction categories, we could still pre-compute the categories on each account and scrape aggregations made on those categories.
More straightforwardly, putting aside categories, there is one useful aggregation in our data already. The account balance is the sum of transactions and is a great example of a gauge. It is the current state of your account or card balance, which rises and falls over time as you make transactions.
Fin
And this is where I call it a day. We noticed already that there are problems with the ingestion, getting the timestamps we desire. There are also problems doing keyword-search on our fields, and now we see that the event-centric nature of the data is not a fit for Prometheus. We didn’t look directly at the queries yet, and there’s surely some way we can get them to work, but it’s already clear that Prometheus isn’t the right tool to solve this problem. At what point would you have decided this wasn’t the right tool? What would you have used instead?